要約
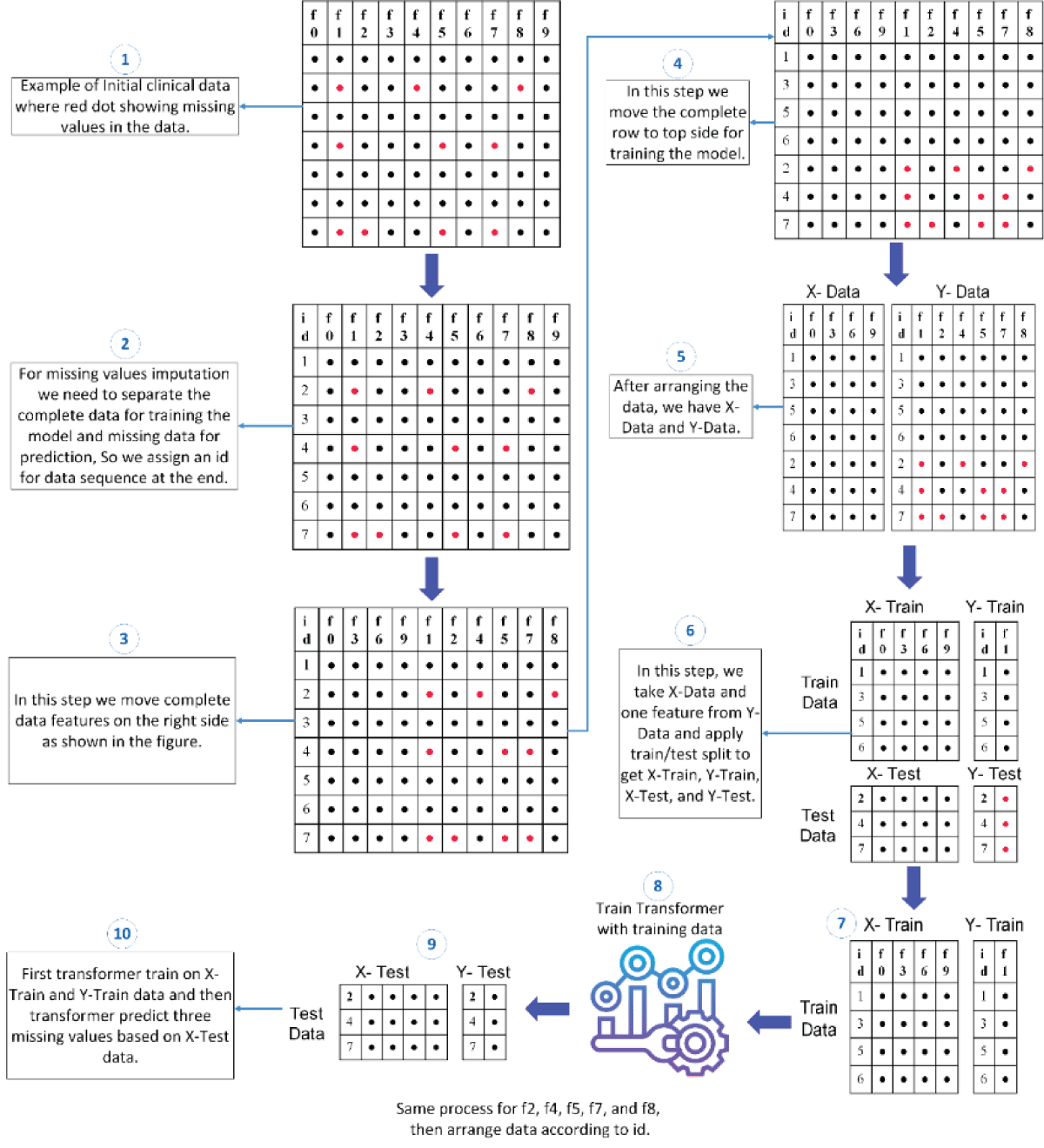
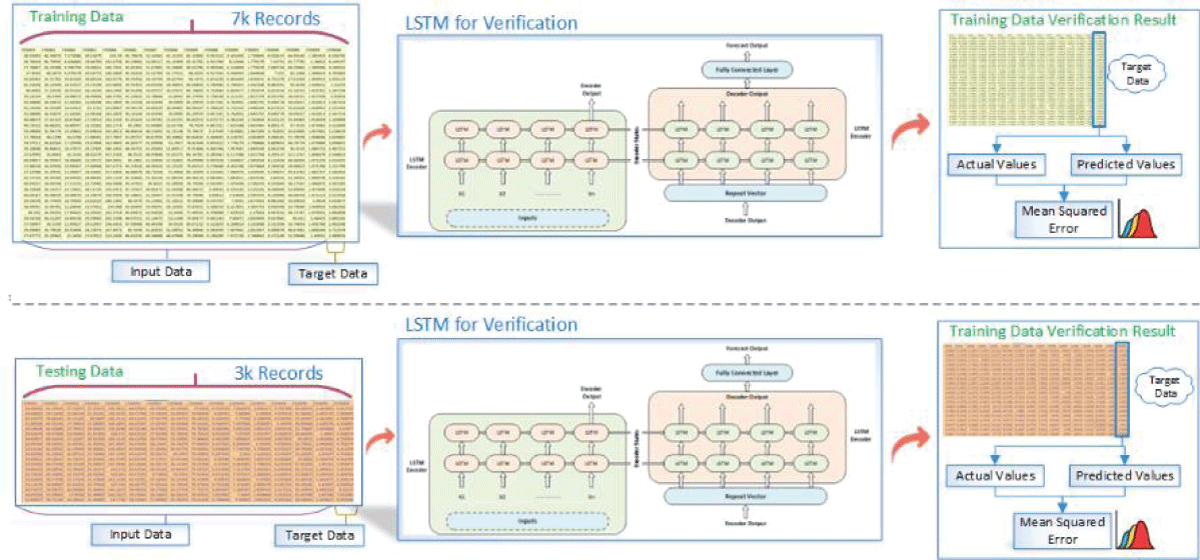
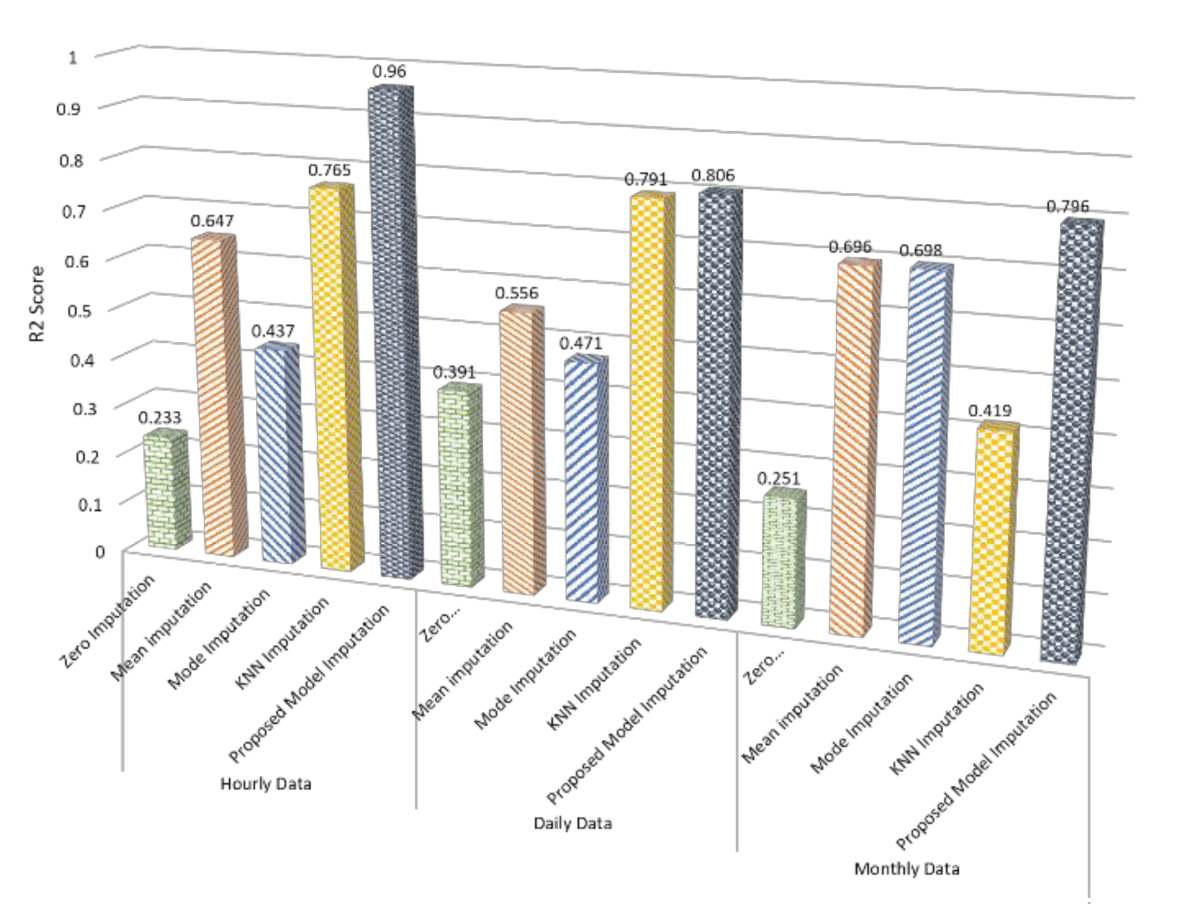
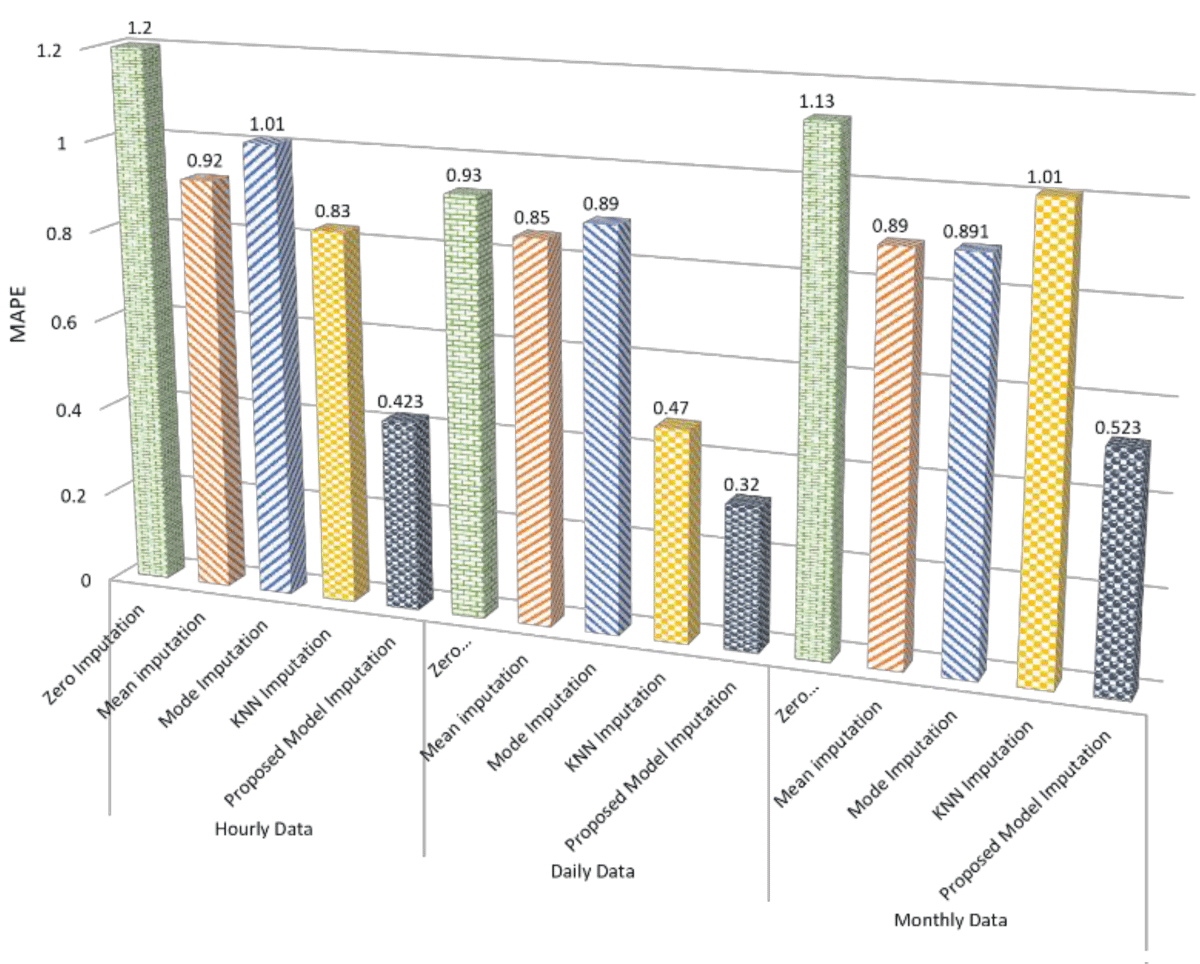
This paper tackles the vital issue of missing value imputation in data preprocessing, where traditional techniques like zero, mean, and KNN imputation fall short in capturing intricate data relationships. This often results in suboptimal outcomes, and discarding records with missing values leads to significant information loss. Our innovative approach leverages advanced transformer models renowned for handling sequential data. The proposed predictive framework trains a transformer model to predict missing values, yielding a marked improvement in imputation accuracy. Comparative analysis against traditional methods—zero, mean, and KNN imputation—consistently favors our transformer model. Importantly, LSTM validation further underscores the superior performance of our approach. In hourly data, our model achieves a remarkable R2 score of 0.96, surpassing KNN imputation by 0.195. For daily data, the R2 score of 0.806 outperforms KNN imputation by 0.015 and exhibits a notable superiority of 0.25 over mean imputation. Additionally, in monthly data, the proposed model’s R2 score of 0.796 excels, showcasing a significant improvement of 0.1 over mean imputation. These compelling results highlight the proposed model’s ability to capture underlying patterns, offering valuable insights for enhancing missing values imputation in data analyses.