要約
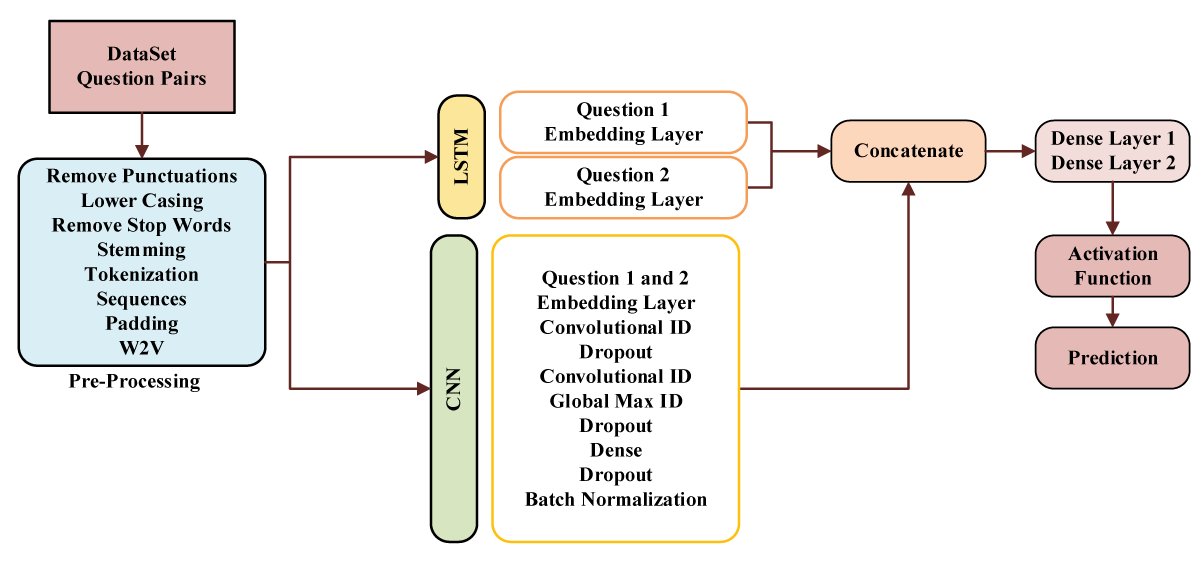
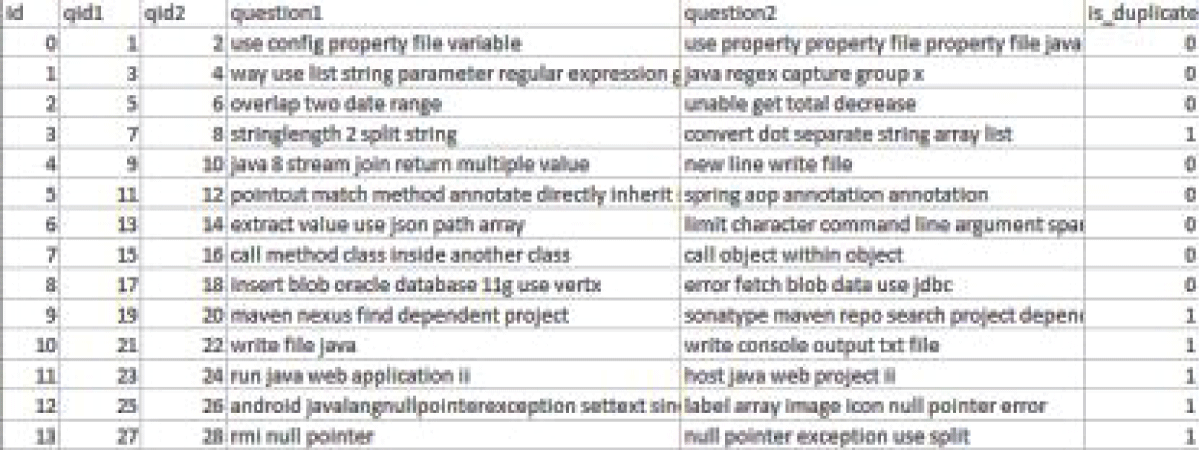
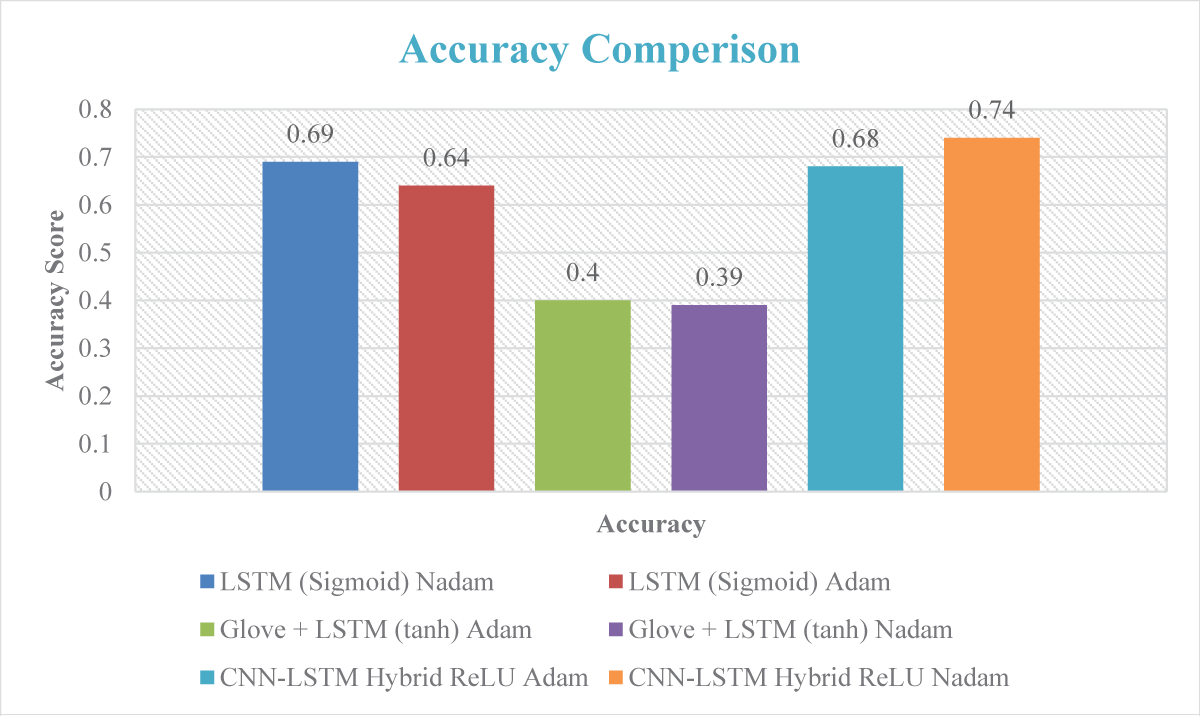
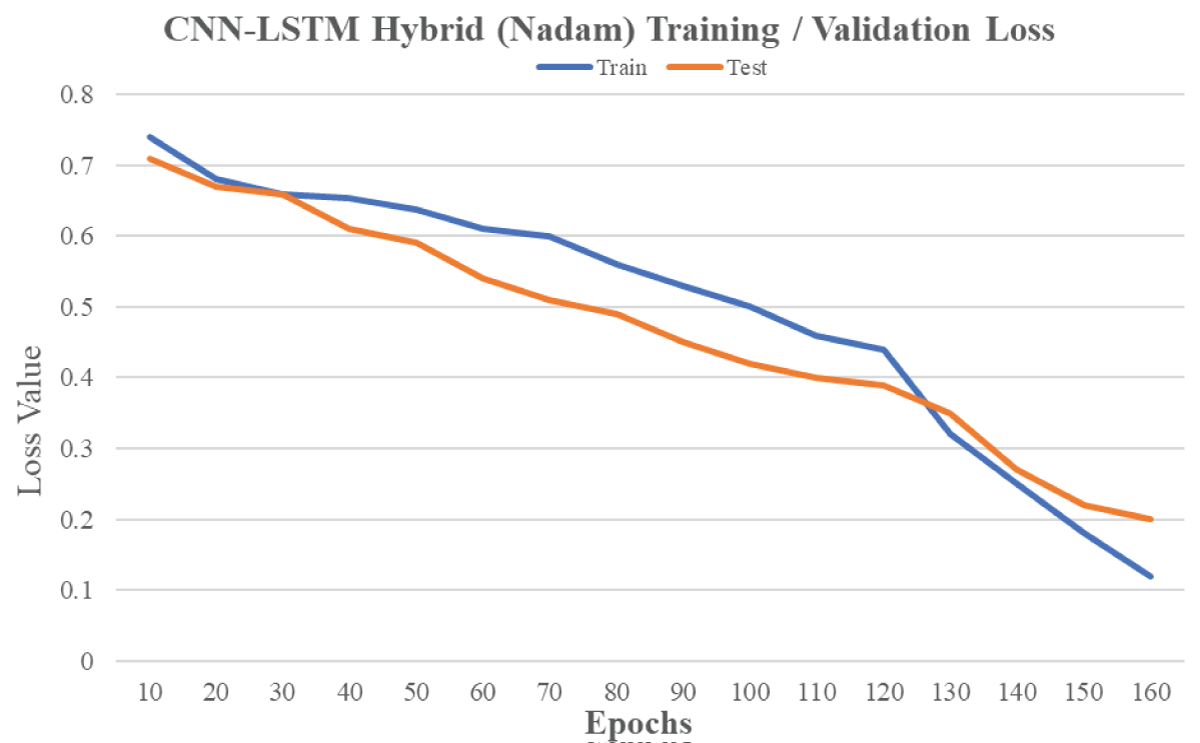
This study provides a novel way to detect duplicate questions in the Stack Overflow community, posing a daunting problem in natural language processing. Our proposed method leverages the power of deep learning by seamlessly merging Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks to capture both local nuances and long-term relationships inherent in textual input. Word embeddings, notably Google’s Word2Vec and GloVe, raise the bar for text representation to new heights. Extensive studies on the Stack Overflow dataset demonstrate the usefulness of our approach, generating excellent results. The combination of CNN and LSTM models improves performance while streamlining preprocessing, establishing our technology as a viable piece in the arsenal for duplicate question detection. Aside from Stack Overflow, our technique has promise for various question-and-answer platforms, providing a robust solution for finding similar questions and paving the path for advances in natural language processing.